
2022年7月6日,第3期Insight Time前沿技术交流分享会上线。
本期的Insight Time分享会邀请到悉尼大学的在读博士生Yae同学,分享主题为《决策大模型:一种通过无标签视频预训练的方法》。
以下是视频和文字实录。
研究背景与意义
近年来,自然语言和计算机视觉的工作证明了数据集上预训练大型的通用基础模型对于上下游任务的有效性。然而对于序列决策任务,由于需要和大量无标签数据交互的特点,难以利用常用的大模型训练的监督和自监督学习的技术。
针对这一技术难点,Yae同学给大家介绍一种半监督模仿学习方法,将训练大型通用模型的范式扩展到序列决策领域。

随着人工智能技术的发展,大模型预九游体育训练技术已经在计算机视觉、自然语言处理中取得一些比较惊人的成绩。Yae同学展示了两个例子。首先是clip的一项通过和ImageNet上预训练模型的对比的工作,通过比较抽象的类素描的识别率取得了一个优异的预训练效果。其次是DALL-E,这是一个新的生成模型的工作。随着这个技术的迭代,它通过利用clip技术融合了大模型以后,也达到了一个非常惊人的效果。
大规模预训练遇到的困难与挑战
这些在大模型预训练技术在计算机视觉和自然语言处理中取得的成绩,让人不由得想到这种训练方法能否运用到决策大模型之中来增强决策的泛化能力。Yae同学指出,这种大规模预训练技术会面临到一些问题。
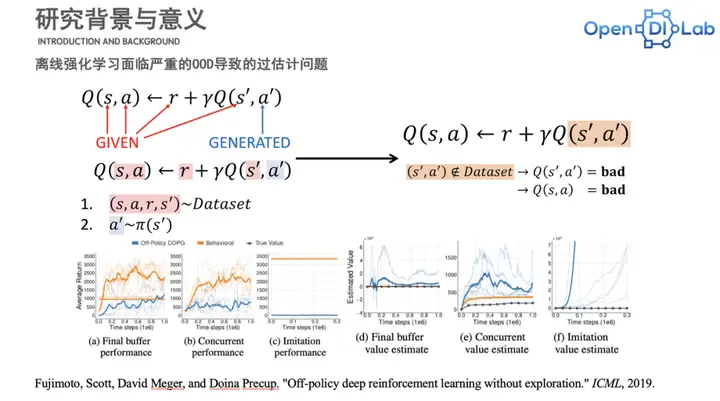
强化学习作为序列决策任九游体育务中的重要方法,很难与大规模离线数据的训练范式相结合。在强化学习中,训练范式一般会要求数据是智能体通过与环境交互产生的。而在计算机视觉中,模型都是利用大规模的离线数据来训练的。
标准的强化学习在有很大规模数据的时候,它本身可以用一些常见的算法(诸如PPO,DQN或SAC)直接部署到离线数据中去进行训练,但这时会出现在数据集分布之外(OOD,out of distribution)的过估计问题。这个问题会导致常见的一些标准的online和off policy的强化学习在这个设置中失效。
在现实生活中我们所能拿到的大量数据,比如视频和自然语言,是不可能带有action和reward这样的标九游体育签的,如何获得大量的有标签数据(包含action和reward)仍然是一个待解决的问题。
视频预训练模型
基于以上种种问题,无标签的视频和自然语言描述成为训练一个决策大模型的解决方案,这也是Yae同学所介绍的决策大模型:一种基于视频预训练的方法。
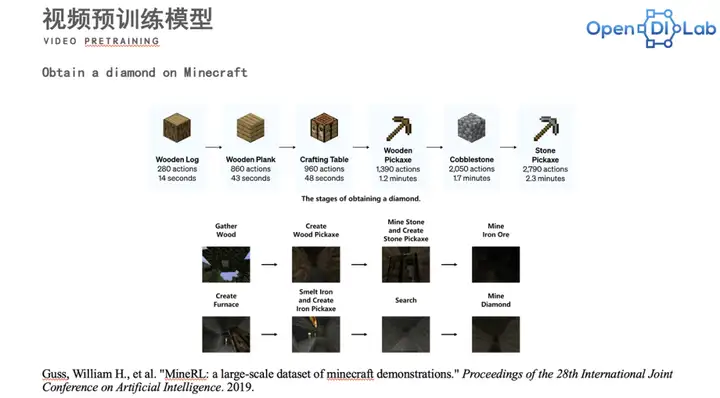
Yae同学首先介绍了决策大模型基于视频预训练方法的环境和任务。这个任务的环境在在Minecraft之中。在这个环境中,以挖到钻石为任务,这是一个非常长的决策序列过程。在这个任务中,如图所示,挖钻石所需要的一些材料被列出。我们会收集一些包含视频和对应动作的专家数据,基于这些数据我们会训练一个IDM模型。IDM通过输入一个多帧的视频可以输出对应某一帧的一个ac九游体育tion。根据这个训练好的模型,我们自然而然地可以对无标签的视频进行标注。这使得网络上收集来的无标签的视频就变成了一个有伪标签的视频的合集,之后可以再利用模仿学习的方法来训练序列决策模型。
数据的收集
在这个案例中收集数据的步骤,其实质是利用视频数据通过模型转化为决策。在这个过程中,大模型的预训练可以被分成三个步骤:
第一步:收集大量的视频序列,即收集上千上万个小时没有标签的视频。然后通过一些关键词去筛选出一些比较纯净的视频段,用来做作为无标签视频的一个数据源。
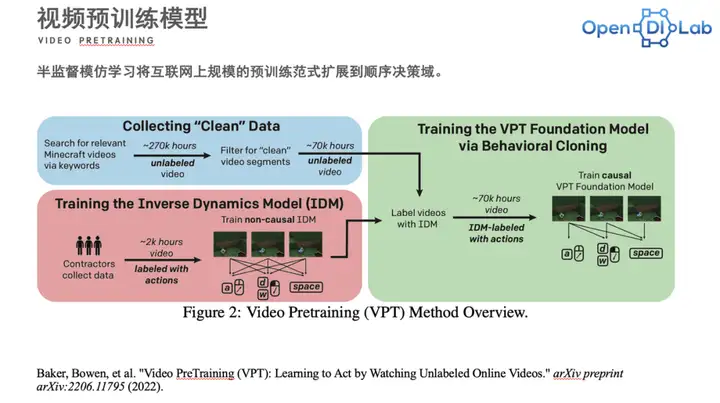
第二步:让一些专家通过一个模拟器收集数据。这个数据收集的过程中会有对应的action,标注视频。
第三步:有了视频以后便可以去训练一个双向非因九游体育果的IDM模型,通过多帧的一个观测来预测当前的一个action。
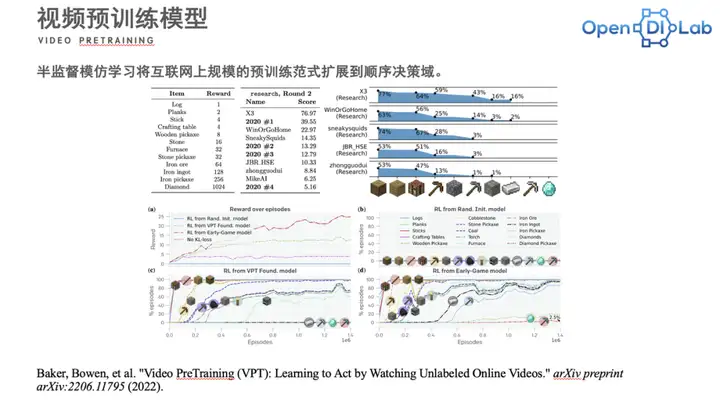
研究成果在NIPS上,决策大模型的挖钻石赛道已经举办了两届了。在上一届的research赛道中,100个episode搜索测评下来的平均得分是76分。Yae同学表示,76分大概对应在得到矿石(Iron ore-Iron ingot)这一步。而在最新的结果中(下图右下角)得到矿石这一步和挖到钻石这一步其实还有很大的gap,距离挖到钻石还有很长的路要走。
总结与展望
Yae同学又分享了他对于决策大模型未来的预期和展望。Yae同学认为,决策大模型的一个趋势是去利用一些无标签或者弱标签的数据来使得训练建模做得更好。除此之外,决策大模九游体育型可以与诸如decision transformer之类离线强化学习序列建模的工作相结合,让这个模型变得更加完善。亦或者用多模态数据去做一个大模型,做controllative learning的训练。罗马不是一日所建成的,而决策大模型的罗马有很多条路可以抵达。
参考文献[1]Levine, Sergey, et al. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. 2020.
[2]Sascha Lange, Thomas Gabel, Martin Riedmi九游体育ller. Batch Reinforcement Learning. Book Chapter, “Reinforcement Learning: State of the Art,”2012.
[3]Scott Fujimoto, David Meger, Doina Precup. Off-Policy Deep Reinforcement Learning without Exploration, ICML 2019.
[4]Fan, Linxi, et al. "MineDojo: Building Open-Ended Embodied Agents with Internet-Sc九游体育ale Knowledge." 2022.
[5]Radford, Alec, et al. "Learning transferable visual models from natural language supervision." International Conference on Machine Learning. PMLR, 2021.
[6]Guss, William H., et al. "MineRL: a large-scale dataset of minecraft demonstrations." Proceedings of the 28th Internation九游体育al Joint Conference on Artificial Intelligence. 2019.
[7]Baker, Bowen, et al. "Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos." arXiv preprint arXiv:2206.11795 (2022).