
在当今科技飞速发展的时代,人工智能无疑是最耀眼的 “明星”。而大模型,作为人工智能领域的核心驱动力,正引领着各个行业的深刻变革。但大模型的运行,离不开强大算力的支撑,算力已然成为这场科技竞赛中的关键 “燃料”。就在最近,DeepSeek 与华为昇腾算力平台的合作,犹如一颗重磅炸弹,在科技圈掀起了惊涛骇浪,解决应用大模型 “算力刚需” 的新征程,就此开启。
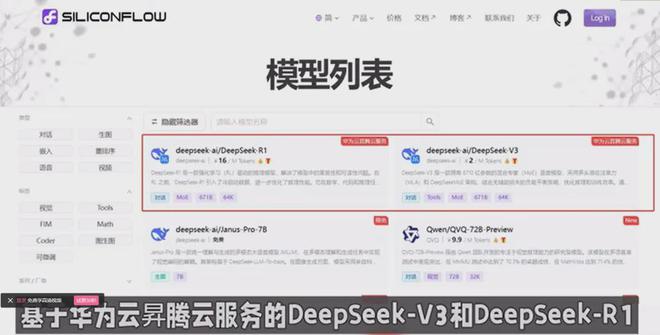
DeepSeek,近年来在大模型领域崭露头角。它以低成本、高性能以及开源的特性,迅速吸引了业界的目光。其 API 成本仅为 OpenAI 的三十分之一,这对于众多渴望运用大模型技术,却又受限于高昂成本的企业来说,无疑是一大福音。不仅如此,DeepSeek 通过创新训练模式,利用基础模型生成高质量合成数据,再结合少量行业数据就能训练模型,突破了数据限制的瓶颈。同时,它将推理资源池的门槛降至百卡/千卡范围,让更多企业能够 “踮起脚尖”,触摸到大模型技术的 “果实”。
华为昇腾算力平台,同样实力不凡。昇腾芯片,如昇腾910B3,以及 CANN 软件栈,为 AI 计算提供了坚实的底层基础。尤其是在面对大模型运行时,华为昇腾展现出了卓越的全栈优化能力。通过自研推理加速引擎、混合云部署等技术手段,实现了从硬件到软件的全方位优化,极大地提升了算力的使用效率。
当 DeepSeek 与华为昇腾相遇,一场 “化学反应” 就此发生。双方的合作,堪称优势互补的典范。华为昇腾的算力平台为 DeepSeek 模型提供了高效的本地化部署支持,尤其在端侧应用场景中,显著降低了延迟和算力成本。而 DeepSeek 的大模型技术,也让昇腾算力有了更广阔的用武之地,两者相得益彰。
从技术突破层面来看,合作成果令人瞩目。华为昇腾大EP推理方案,为解决大模型运行中的技术难题提供了有力的解决方案。在大规模专家并行(EP)技术成为趋势的当下,昇腾大EP方案实现了单卡性能提升3倍的极致吞吐,同时降低了单卡显存占用,使单卡并发提升到3倍。Decode 时延降低50%以上,大大提升了用户体验。在MoE负载均衡方面,通过自动寻优、自动配比、自动预测、自动降解等技术,实现了备份节点和副本专家的灵活可扩展、高可用和极致均衡,避免了专家负载不均的问题。
从产业生态角度而言,这一合作也意义深远。华为凭借全自研的优势,软件开源开放,兼容主流框架,拥有自己的昇思深度学习框架和MindIE推理引擎,也支持vLLM等业界框架,为开发者和企业提供了丰富的选择。而DeepSeek遵循MIT协议开源,吸引了大量开发者参与。双方合作,吸引了更多企业加入到 AI 技术的研发与应用中来,加速了AI技术的普及和商业化落地。如今,合作成果已在金融、智能汽车、政务等多个领域开花结果。中软国际为金融客户开发的鸿蒙App接入DeepSeek 模型,紫光股份推出基于 DeepSeek 的灵犀使能平台,三大运营商智算平台全面接入昇腾优化的 DeepSeek 模型,广州、深圳、郑州等地的政务云平台实现基于昇腾的 DeepSeek 部署……

展望未来,随着双方合作的不断深入,我们有理由相信,这场由 DeepSeek 与华为昇腾引发的算力革命,将持续推动人工智能技术在各个行业的广泛应用,让科技真正赋能生活,改变世界。在全球科技竞争日益激烈的今天,这样的合作,也为我国在人工智能领域赢得了更多的话语权和竞争力。