
广义上,AI芯片是用于运行AI算法的专用处理器,与传统芯片(如CPU)的区别在于专用性或通用性的侧重上。下面的几类芯片,都可以执行AI算法。

某种程度上,GPU和FPGA也可以视为AI芯片,不过ASIC类的特点鲜明,因此最具有代表性。
AI芯片遵循一个硬件设计规律:
通过牺牲一定通用性,换来特定业务的效率提升
一个好理解的例子是比特币挖矿。
比特币的共识算法是SHA256算法,基于哈希运算,所以不存在反向计算公式,只能靠矿机去穷举海量的可能值。对于每个区块,最先尝试到正确值的矿工,将获得挖矿奖励。对于矿工计算速度越快,获得奖励的期望就会越高。
在CPU作为主流挖矿方式的时期,一位论坛ID为Laszl九游体育o的程序员,发现GPU的挖矿效率远远高于CPU。于是他仅用一块9800显卡,就挖出了超过8万个比特币。
Laszlo:As far as I know I was the first to release a GPU miner.
Laszlo除了是最早用GPU挖矿的人外,还做过一件具有里程碑意义的行为艺术:用10000枚比特币买了2个披萨。
关于这段有趣的历史,参见我之前的文章:
接下来的一段时间里,GPU得益于算力和能效上的巨大优势九游体育,逐渐成为了主流的挖矿芯片。
不过到了现在,再用GPU挖比特币,已经几乎不可能了。例如RTX 3090显卡,在超频情况下,每秒能执行126.5M次SHA256计算,而比特币的全网总算力已经超过178.60EH/s,等价于14000亿块RTX 3090显卡的算力总和。
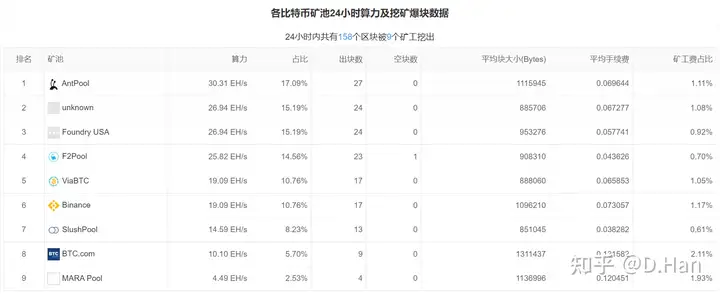
这些海量算力主要来自ASIC矿机,其计算芯片就是面向执行SHA256算法去进行架构设计。这使得ASIC矿机在挖矿效率上碾压显卡,甚至于单矿机就能胜过超算中心。
但是ASIC矿机在硬件上牺牲了通用性,导致无法执行其他计算任务,甚至于无法挖非SHA256算法的区块链货币,九游体育如以太坊。
AI芯片面向AI算法设计,牺牲通用性,超高的执行效率。
在比特币挖矿的例子中,能看出专用芯片最为适合:算法(or算子)固定,且相对简单的应用场景,比如比特币的SHA256算法。
AI芯片跟矿机的特点一致,重视专用场景下的运算效率,但落地场景不同。
AI芯片的目的是高效率地执行AI算法,因此也会被称为AI加速器,并衍生出了一大堆名字,如NPU(神经网络处理器),TPU(谷歌·张量处理器),APU(AMD·加速处理器)。虽然名字上不一样,但性质上颇为类似。

下面用谷歌的初代TPU(2016年)举例。
图中对比了若干主流AI算法的推理表现,初代TPU相比同时代的CPU/GPU,效率可谓摧枯拉朽。TP九游体育U不仅是性能强悍,在能效上依然甩出CPU和GPU数十倍。
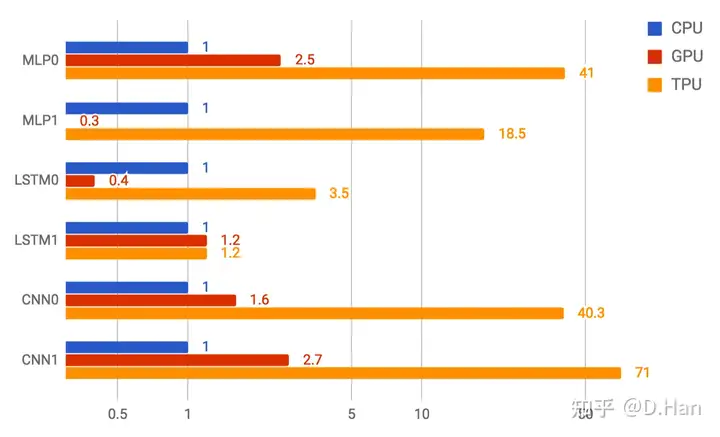
有意思的是,根据TPU项目的技术负责人(诺曼·乔皮)所说,在工程开始时,他们连团队都没组齐,还要手忙脚乱的去招聘RTL和验证工程师。
Norm Jouppi:We did a very fast chip design. It was really quite remarkable.即便是仓促上阵,但初代TPU的设计,验证,流片,加上部署,整体流程只耗费了15个月时间。
这体现了AI芯片的一个特点,架构相比通用芯片(CPU/GPU)要简单得多,使得TPU团队能够在如此短的时间内,快速打造出一款全新的AI芯片。
下图是TPU的模块面积图,其中黄色九游体育是计算相关,蓝色是数据相关,绿色是读写相关,而红色则是控制相关的电路,仅占了芯片面积(die)的2%。
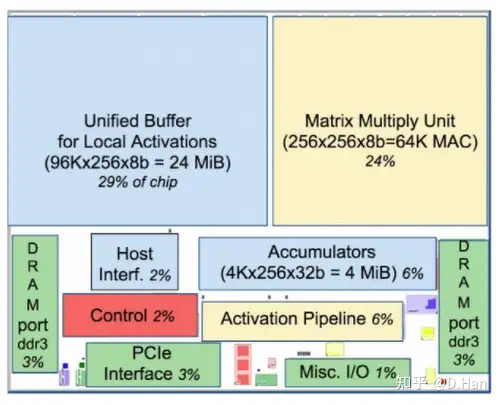
TPU只需面向卷积神经网络的运行,因此可以减少控制逻辑,且各项延时相对固定,运行的稳定性高。
CPU和GPU因为要面临复杂多样的计算任务,控制逻辑复杂的多,造成控制电路的面积大,也更难设计。
想进一步了解AI芯片效率奇高的机理,就要了解些AI算法
AI算法通常是基于卷积神经网络,最基本且最主要的操作是『卷积』。
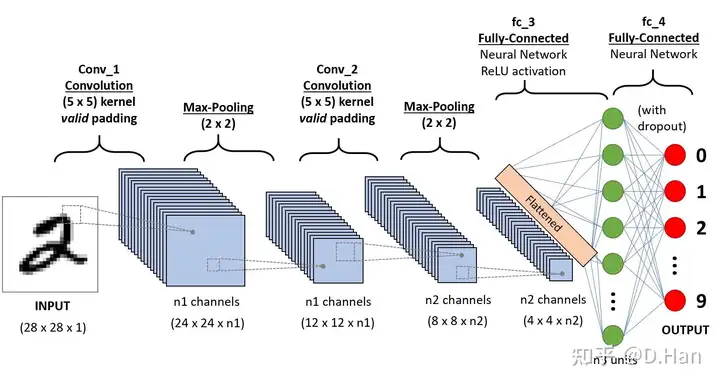
注意,此处『卷积』定义不同于信号处理中的卷积。以最常见的3x3卷积为例,计算过程如下图所示:
当输入层数C_in=1时,每个输出像素为9个输入像素值,对应加权,然后求和得到;此时,获取每个输出像九游体育素的数值,需执行9次乘法和9次加法;此时,当前层共需要9个参数,对应3x3卷积的9个像素点。如果输入层数C_in不为1,则执行9 x C_in次乘法和加法。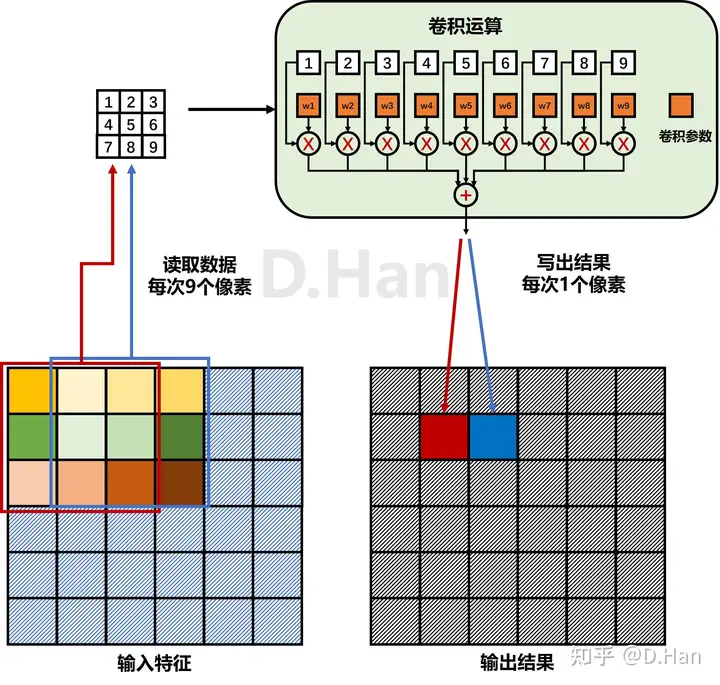
举个更具体的例子,在1080P分辨率下,1个4层输入4层输出的卷积层:
需要执行 4\times 1080 \times 1920 \times 4 \times 9 = 300 \rm M 次乘法和加法当层数较大时,参数量会激增。对于一个512层输入和512层输出的卷积层:
需要载入 512 \times 512 \times 9 = 2.4 \rm M 个卷积参数上述介绍的仅仅是一个卷积层,而真正的卷积神经网络通常由多个卷积层和其他算层蹭相互连接构九游体育成[3]。
为了更好地实现模型的推理加速,需要总结实际模型的特点,分析出性能瓶颈,进而做出针对性的优化。
TPU团队在2016年时,统计过6个谷歌产品和工具中的若干类常见神经网络,详见下表:
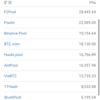
模型类型网络层数参数数量部署比例MLP0520M61%MLP145MLSTM05852M29%LSTM15634MCNN0168M5%CNN189100M常见模型的参数数量从500万到1亿个之间,可见:
卷积神经网络的推理,经常需要大量的乘加运算和大量的参数载入。所以,不仅仅是卷积计算,读写参数造成的IO负担,也可能成为瓶颈。AI芯片:并行化以优化计算瓶颈
面对卷积神经网络的庞大计算量,九游体育CPU在单时钟周期内可执行的运算数有限,极易出现计算瓶颈。GPU则是提升了并行计算性能,将卷积运算等价变换成矩阵的乘加运算,成为了神经网络训练的主流硬件。
模型加速的核心是提升并行化水平,在同一个时钟周期内,进行尽可能多次的运算。TPU重新设计了专用的硬件架构:脉动阵列(systolic array)。
单个时钟周期可执行的运算数CPU一两个CPU(vector extension)数十个GPU数千个TPUv1256 * 256 = 65536个TPU的脉动阵列参见下图[1],计算结果并非直接输出,而是在脉动阵列中按规律“流动”,等完全计算好后才输出保存。不仅增加了并行度,还实现了参数的复用,避免九游体育了反复载入。脉动阵列结构精妙,后续有机会可以单独写回答来介绍。

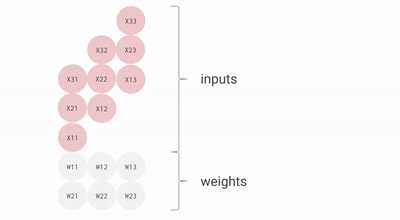
TPU的脉动阵列在每个时钟周期能执行65536次8位整型数的乘加运算。在700MHz的主频下,实现了65536 * 700,000,000 * 2 =92Tops@INT8的惊人算力。
AI芯片:高速的片上存储以缓解读写压力
上文提到,谷歌部署的神经网络中,参数数量从500万到1亿个不等,且中间结果也有很大数据量。
如果卷积运算单元(如脉动阵列)从DDR(内存)上,频繁进行:
加载参数读入数据写出结果类似木桶效应,决定盛水量的是最短的那块木板,即性能瓶颈。上述密集的DDR读写操作,使得IO速度容易成为模型推理的性能瓶颈。
于是,初代TPU搭载九游体育了28M字节的片上存储器(On-chip memory, OCM),虽然成本较高,但读写速度远胜DDR内存。而第二代TPU更是不惜成本,十分奢侈地搭载了16GB的HBM存储单元,其IO速度达到了600GB每秒。
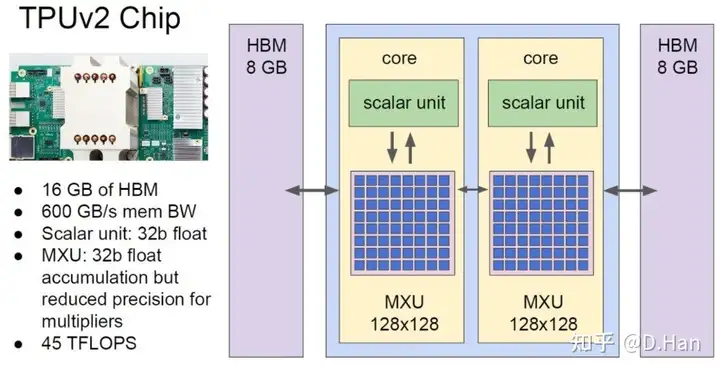
有了高速缓存(OCM or HBM)后,运行时就可以将频繁使用的参数,提前载入到高速缓存中,然后卷积核便可以快速读取所需数据,无需反复从内存上载入。不仅如此,片上存储器还可以保存网络运作的中间结果,避免在内存上中转(写入+读回),从而显著降低内存的IO压力。
这里高速缓存的作用类似于传统CPU中的L3缓存,目的是有效缓解内存的带宽压力,让卷积核的强大算力得到充分发挥,避免出现空等数据载入的九游体育情况。
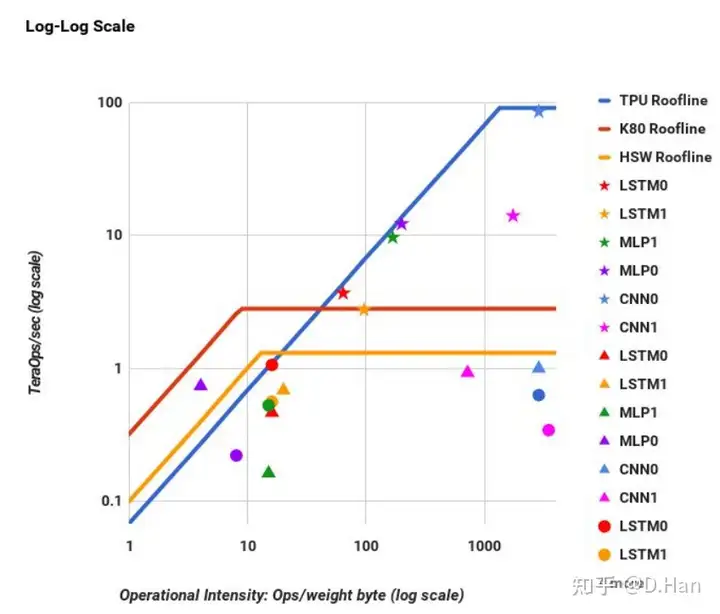
下图出自论文[2],第一作者TPU项目的技术负责人(诺曼·乔皮)。论文实验并统计了若干主流模型在TPU/GPU/CPU上的运行表现。
横轴为所需算力除以需从内存载入的数据量,代表单位内存数据载入对应的计算密度,而纵轴为实际发挥的算力。斜线部分代表算力表现被内存IO带宽制约,而水平部分代表性能已充分发挥,即被算力制约。
如图所示,TPU(蓝线)在高计算密度时,效果明显优于CPU(黄线)和GPU(红线)。可见在高计算密度情况下,TPU能发挥更大优势。而28MB的片上存储能够提前缓存参数和中间结果,避免卷积核频繁进行内存对鞋,从而提升计算密度,让TPU运行更加高效。
软硬结合:卷积神经网络的量九游体育化算法
在硬件设计之外,为了让AI芯片更高效的运行模型,需要对AI算法做轻量化处理。
一个常见且直观的方法是进行『模型量化』,可以显著降低参数大小和计算量。
当前的神经网络训练基本都基于浮点运算,在GPU上训练和推理时,通常使用32比特或64比特来表示一个浮点数。
如果使用更低的比特数,比如改用8个比特来表示数字,会极大降低参数大小和计算量。
谷歌:如果外面在下雨,你可能不需要指导每秒有多少雨滴落下,而只是想知道,下的大雨还是小雨[1]。如下图[1]是使用8比特整型数去近似32位浮点数。
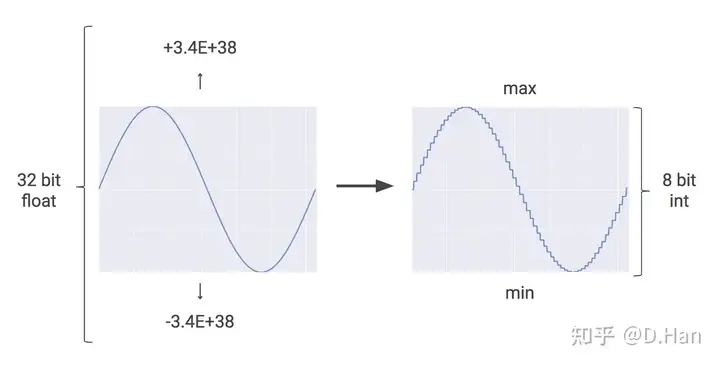
量化等于带来了一定的量化噪声,而好的神经网络会具备一定的抗噪能力,因此量化后算法的精度损失会是有限且可控的。
量化的另一九游体育个好处是,如果将模型的输入和参数均量化成整型数(如int8/uint8),没有了浮点计算,能让硬件设计更加简化。如上文介绍到,初代TPU仅支持整型运算,不仅是因为整型数运算在硬件上更加高效,且电路会简单很多。
目前主流的量化方法有两大类:
量化方法简称量化能力优势劣势量化训练QAT低于8bit极致的精度和效率需要训练数据
训练时间长学习门槛高训练后量化PTQ可达8bit不需要训练数据
转换速度快使用门槛低存在精度/效率损失QAT在训练模型时就使用量化算子,可以最大地避免精度损失,但不能使用现有的浮点模型,需要从头开始去重训模型。
PTQ则是对现有的浮点模型做量化,虽然量化后的模型精度和效率不通常如QAT九游体育,但由于不需要重新训练模型,使用门槛更低更稳定,还是有很大的使用需求。而如何减少精度损失,是PTQ方案在不停探索的目标,也衍生出了多种思路,例线性数量化和对数量化。
软硬结合:执行效率和硬件成本的最佳兼顾
除必不可少的3x3卷积外,常见的神经网络算子多达数十种(如ONNX包含80+算子)。
出于芯片成本,设计难度和运行效率的考虑,现有的AI芯片都只能原生支持部分算子。
在模型训练时就需要了解和考虑硬件能力,尽量使用AI芯片能高效支持的算子,以提升部署后的运行效率。反过来,AI芯片的硬件设计时,同样需要考虑算法设计的需要,尽量支持更多的常用算子,以提高模型设计的自由度。
如果厂商具备软硬件之间的协同九游体育开发能力,就可以在模型精度,芯片成本,推理速度之间,达到非常好的兼顾,实现1+1>2的效果。
这也是越来越多终端厂商选择自研AI芯片的原因,而AI芯片厂商也经常会打包算法出售。
其他:
AI芯片除了硬件外,软件栈(工具链)的设计也是非常重要且有难度的,不仅是模型量化,还包括编译器设计。
在编译环境,为追求更高的硬件效率,需要研究非常复杂的调度问题,这是我目前的主要工作内容。日后有精力会单独写回答分享。
参考资料:
[1] 重点参考:An in-depth look at Google’s first Tensor Processing Unit (TPU)
[2] https://arxiv.org/ftp/九游体育arxiv/papers/1704/1704.04760.pdf
[3] Convolutional Neural Network (CNN)
[4] 【国产自研芯片】为了AI暗光相机,工程师竟去密室拍NPC和小姐姐?_哔哩哔哩_bilibili
[5] 下书(一直在看):
